How many Git repos?
I’ve been pondering how to split (or not as the case may be) code between separate Git repositories. Say we’re developing a web-application that consists of three modules: a SQL database schema, a Haskell web server, and a web client built using Node. We could put this code into repositories in different ways; for example:
Three separate repositories, one for each module. Two repositories, with DB and web server grouped. One repository for all three module.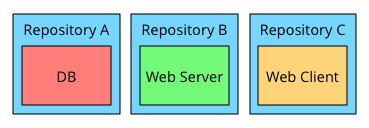
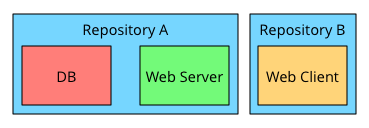
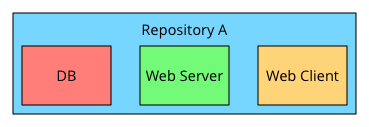
The first alternative – one repository per module – seemed compelling at first. This encourages clean separation, lends itself to using Git tags for versions, and allows us to grant access to code on a need-to-know basis.
For over 2 years, that was what we did in our startup, but it wasn’t as clean and convenient as I had first imagined.
Following the one-repository-per-module policy, we created a new repository when we broke out one part of the project into its own library. For example, we put our email-handling code into its own module and therefore also in its own repository. The number of repositories we needed to build the product steadily grew – in our case to over 15.
Managing the code in separate repos was inconvenient: pulling changes from all repos in case something changed, creating versions and specifying dependencies between modules, adding the same branch to many repos when changes touched more than one repo, and the inability to make atomic API changes that spanned more than one module. I think Jack O’Conner expressed it nicely:
So the question isn’t “One big repo or many small repos?” It’s actually “One big repo or many small repos with tooling.”
Git is a powerful tool and I now think that project
I use “project” to refer to an effort to develop a set of interrelated functionality. For example, Google’s search engine would be one project (and include AdWords). YouTube and Android would each be a separate project. Thus, a project can comprise several customer products and is determined more by how interrelated the functionality is and how the project is delivered and deployed than whether the result looks like a single thing or not.
code and related artifacts should be kept in a single large
If we use one large repository, problems with our Git workflow will be amplified due to a higher number of commits and contributors. I find the approach Sandofsky explains in Understanding the Git Workflow compelling.
repository, except for open-sourced modules
Open-sourced modules are usually made available via public package repositories (npm, Hackage, etc.) which solves some of the dependency problems, but slows down iteration cycles and increases overhead.
. You end up with a single repository to pull and push, you can make atomic commits when changes span many modules, you can naturally include build and test code, you have a single entry-point for new developers, you have a combined view of what has changed in the project, you don’t have to work across several repositories to pin-point where bugs were introduced, and you can modularise and re-organise with minimal overhead.
I have yet to find a compelling argument for splitting project code into many repositories, except if Git struggles with the repository size or if parts of the code are highly sensitive and require granular access control. If you have one, I’d be interested to know.
Further reading
Gregory Szorc, On Monolithic Repositories, https://gregoryszorc.com/blog/2014/09/09/on-monolithic-repositories/ ()
Benjamin Sandofsky, Understanding the Git Workflow, https://sandofsky.com/blog/git-workflow.html ()